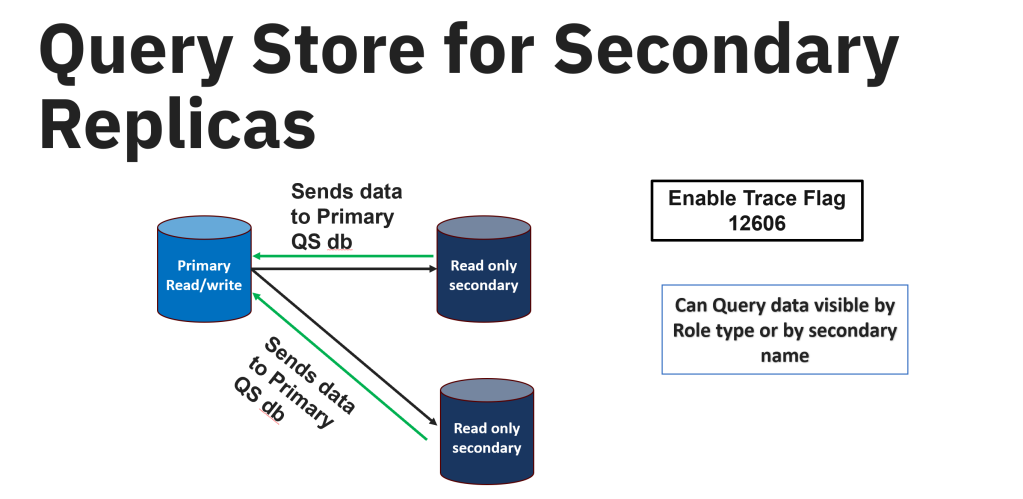
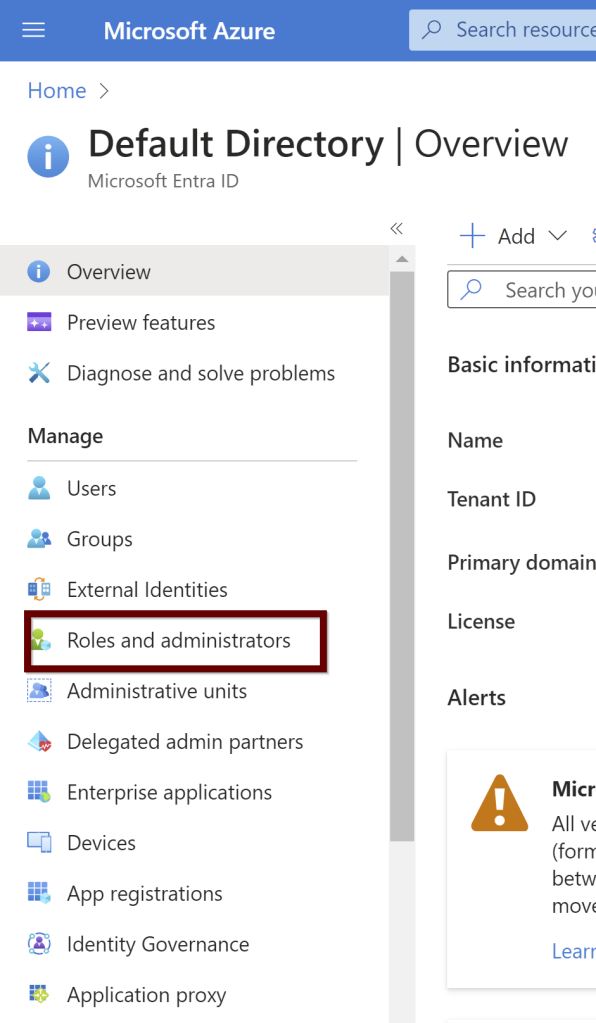
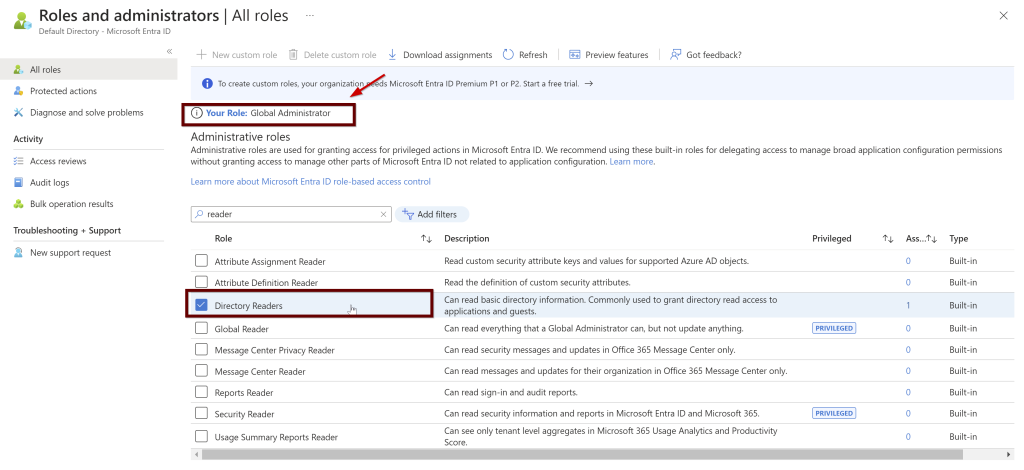
Thank you Mala for hosting T-SQL Tuesday for August month. Mala asked us to write about the Database version control and what tools we use to manage our database code. Please find the original invite here.

Earlier in my career as a DBA, the database code was managed with comments in the code to know who changed what, when, and the purpose of the change. It was tough to manage the code since many developers forgot to put in these comments properly. This is not a reliable way to maintain the code.
Then we decided to use the source control. Version control is where your changes in the code are tracked over time as versions. If in case you need to roll back to the previous version, you have the correct version in place as a point-in-time snapshot to retrieve that version back to rollback with much ease. Version control also helps with the collaboration of work by multiple developers working on the same project. There were several tools in the market. You can find the list here.
We used Redgate Source Control with the DevOps Git repository. Redgate Source control is a plugin you use in the SSMS tool. It will connect your databases to the source control systems like Git, TFS etc; Install the Redagte SQL source control tool from here.
We created a Project in the DevOps and select the version control as Git. We then initialize the main branch using the visual studio and clone the branch using the visual studio to local folder. We then connect the SQL database to the source control by connecting to the local folder. This will link the database to the source control. The initial commit will help us push the objects into the source control.
We can also use the Azure DevOps to create CI/CD pipelines to push the changes to each environment before committing the code into production. To find out what the CI/CD pipeline is, please read this Microsoft article.
I have described it very briefly here in this blog post about the database code solution we used but this is a wide topic to learn.
To learn about Azure DevOps implementing continuous integration using DevOps, check the Microsoft learn series here.
I am looking forward to reading the experiences of other SQL Community members regarding their journey with database source control.
Thank you for reading!